

Companies have started paying close attention to the Voice of Customer (VoC) to improve their customer experience. By analysing the reviews and feedbacks of their products and services, they get better insights for what their customers want and in which direction they should venture next.
According toForrester, insight-driven companies will earn $1.8 trillion and are going to outperform their peers by 2021. But even though companies are getting big on data analysis, most of them don’t know how to gain valuable insights from those unstructured data. In other words, most of these companies are data-rich but insight-poor.
Amazon has always been big on reviews. In 2007, after the release of a volume of the popular book Harry Potter, both Amazon and Target sold about 2 million copies but, despite using the same software, Amazon got 1805 reviews and Target only 3. This shows how much work Amazon puts in ensuring its customers’ satisfaction and further emboldens the Customer is King stance of Amazon.
We started exploring the review section of Amazon to get inspired and understand how exactly Amazon extracts insights from it. Soon enough, we noticed that Amazon had integrated a new feature which provided its users with relevant keywords related to the respective product and further showed reviews based on those keywords if chosen by the buyer. Amazon even asks its customers to use these keywords while they are writing a review to get featured.
For example, for Apple Airpods, Amazon shows features and specs related keywords like battery life, camera quality, dual sim, fingerprint, etc..

Given our extensive interest in NLP, we loved this small yet significant addition by Amazon and set out to pinpoint the exact algorithm they might be using for it. We started with several simple methods based on Keyword Extraction like RAKE, TextRank, TF-IDF and moved on to Topic Modelling algorithms such as NMF, LDA, LSA, etc.. After trying out all these different methods, we found that TF-IDF was the only one giving out highly accurate and scalable results.
How we went about extracting valuable insights from product review data

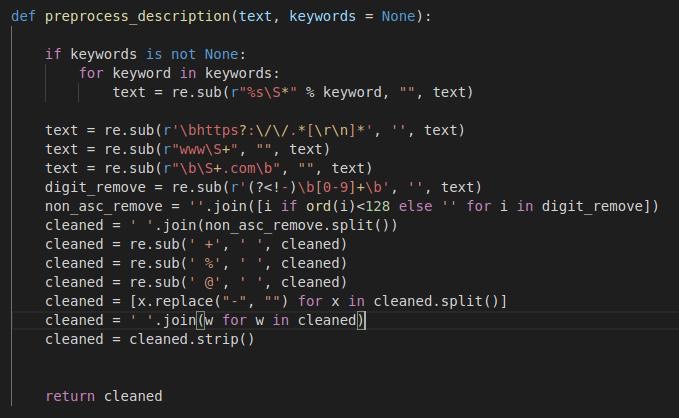
Data Preprocessing
We first gathered product reviews for Apple Airpods from different websites and stored it in a database. One can also choose to serve this data directly to the algorithm via a REST API call. Various Web Scraping tools can also be used to collect more such reviews on one product.
Next, we loaded the data as a pandas DataFrame and used a basic filter to remove reviews which were not in English and were less than 50 characters. Short reviews often skew the data and lack information on specific features and issues.

Keyword Extraction
We then used sklearn’s TFIDF vectorizer to get the review level features. In terms of the hyperparameters, we used the following:
- English stopwords
- N-gram size (2,3)
- Maximum Document Frequency (max_df)=0.9
- Minimum Document Frequency (min_df)=0.01
- Maximum Features = 10% of the Number of Reviews in the dataset
That gave us TFIDF vectors for unigrams, bigrams, and trigrams for all the reviews. However, these vectors were at a document level, and we had around 200 words (if one considers a dataset of 2,000 reviews.) We needed to look for a manageable set of high-value keywords. So, we did a keyword wise roll up for the TFIDF values across all the reviews. Selecting the top 20 keywords after the roll up gave excellent results.

Post-processing
The results, however, were still not perfect. There were a few problems that one would generally notice at this point:
- Incomprehensible keywords like ‘value money’ instead of ‘value for money’ since we dropped stopwords.
- Syntactically similar keywords, e.g., battery great and great battery, good earphones and good earphones.
- Product or company name, e.g., amazon great, apple AirPods etc..
To resolve these issues, we used some post-processing steps to remove product/company names and clear duplicate or syntactically similar keywords. To address the stopword issue, we searched for the phrases back in the reviews and picked up missing words from there.

Final Output
These results for Apple Airpods closely match those from Amazon.
The process can also be extended to analyse reviews from TrustPilot, Glassdoor, Yelp, and other aggregators. Enhancements such as sentiment analysis, user ratings, and trends can also be integrated to add an extra dimension for the users to explore.
So while 74% of firms say they want to be “data-driven,” only 29% say they are good at connecting analytics to action. This is why there’s a need to make tools and technologies more accessible to businesses and, that is what we’re doing.

